

Learning from Interactions

In ILIAD, we are interested in two core objectives: 1) efficiently learning computational models of human behavior (reward functions or policies) from diverse sources of interaction data, and 2) learning effective robot policies from interaction data. This introduces a set of research challenges including but not limited to:
- How can we actively and efficiently collect data in a low data regime setting such as in interactive robotics?
- How can we tap into different sources and modalities --- perfect and imperfect demonstrations, comparison and ranking queries, physical feedback, language instructions, videos --- to learn an effective human model or robot policy?
- What inductive biases and priors can help with effectively learning from human/interaction data?
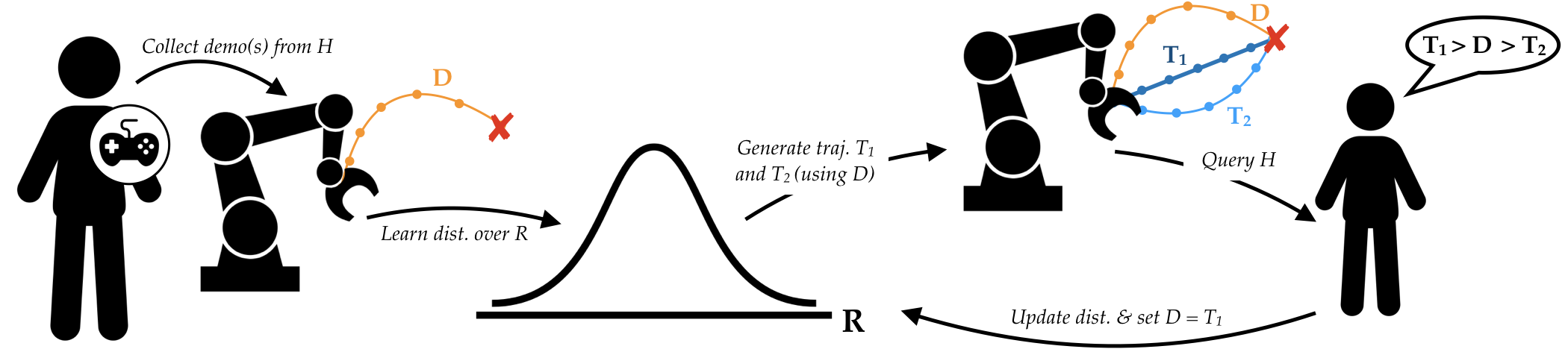
Active Learning of Reward Functions

In our work, we also consider: learning expressive and multimodal reward functions, learning non-linear reward functions, batch active learning of reward functions>, dynamically changing human reward functions, as well as optimizing for the ease of queries to enable a more reliable and intuitive interaction with humans.
Learning from Diverse Sources of Data
We study learning from diverse sources of data from humans, such as optimal and suboptimal demonstrations, pairwise comparisons, best-of-many selections, rankings, scale feedback, physical corrections, and language instructions. We also investigate how to optimally integrate these different sources. Specifically, when learning from both expert demonstrations and active comparison queries, we prove that the optimal integration is to warm-start the reward learning algorithm by learning from expert demonstrations, and fine-tune the model using active preferences. Aside from learning through queries, we also investigate how to understand other sources of human robot interaction, such as physical interactions. By reasoning over human physical corrections, robots can adaptively improve their reward estimates.
Learning from Imperfect Demonstrations
Standard imitation learning algorithms often rely on expert and optimal demonstrations. In practice, it is expensive to obtain a large number of expert data, but we usually have access to a plethora of imperfect demonstrations--suboptimal behavior that can range from random noise or failures to nearly optimal demonstrations. The main challenge of learning from imperfect demonstrations is excavating useful knowledge from this data and avoiding the influence of harmful behaviors. We need to down-weight those noisy or malicious inputs while learning from those nearly optimal state and actions. We develop an approach that assigns a feasibility metric to deal with out-of-dynamics demonstrations and an optimality metric to deal with suboptimal demonstrations [RA-L 2021]. We further demonstrate such metrics can be directly learned from a small number of ranking data, and propose an iterative approach that learns a confidence value over demonstrations and the policy parameters [NeurIPS 2021].
Risk-Aware Human Models
Many of today’s robots model humans as if they are always optimal or noisily rational. Both of these models make sense when the human receives deterministic rewards. But in real world scenarios, rewards are rarely deterministic. Instead, we consider settings, where humans need to make choices subject to risk and uncertainty. In these settings, humans exhibit a cognitive bias towards suboptimal behavior.
We adopt a well-known Risk-Aware human model from behavioral economics called Cumulative Prospect Theory and enable robots to leverage this model during human-robot interaction. Our work extends existing rational human models so that collaborative robots can anticipate and plan around suboptimal human behavior during interaction.


In a collaborative cup stacking task, a Risk-Aware robot correctly predicts how the human wants to stack cups: it correctly anticipates that the human is overly concerned about the tower falling, and starts to build the less efficient but stable tower. Having the right prediction here prevents the human and robot from reaching for the same cup, so that they more seamlessly collaborate during the task! Our work integrates learning techniques along with modeling cognitive biases to anticipate human behavior in risk-sensitive scenarios, and better coordinate and collaborate with humans [RSS 2020b, HRI 2020].
Incomplete List of Related Publications:- Vivek Myers, Erdem Bıyık, Nima Anari, Dorsa Sadigh. Learning Multimodal Rewards from Rankings. Proceedings of the 5th Conference on Robot Learning (CoRL), 2021. [PDF]
- Erdem Bıyık, Dylan P. Losey, Malayandi Palan, Nicholas C. Landolfi, Gleb Shevchuk, Dorsa Sadigh. Learning Reward Functions from Diverse Sources of Human Feedback: Optimally Integrating Demonstrations and Preferences. The International Journal of Robotics Research (IJRR), 2021. [PDF]
- Songyuan Zhang, Zhangjie Cao, Dorsa Sadigh, Yanan Sui.Confidence-Aware Imitation Learning from Demonstrations with Varying Optimality. Conference on Neural Information Processing Systems (NeurIPS), 2021. [PDF]
- Mengxi Li, Alper Canberk, Dylan P. Losey, Dorsa Sadigh.Learning Human Objectives from Sequences of Physical Corrections. International Conference on Robotics and Automation (ICRA), 2021.. [PDF]
- Erdem Bıyık*, Nicolas Huynh*, Mykel J. Kochenderfer, Dorsa Sadigh. Active Preference-Based Gaussian Process Regression for Reward Learning. Proceedings of Robotics: Science and Systems (RSS), July 2020. [PDF]
- Minae Kwon, Erdem Bıyık, Aditi Talati, Karan Bhasin, Dylan P. Losey, Dorsa Sadigh. When Humans Aren't Optimal: Robots that Collaborate with Risk-Aware Humans. ACM/IEEE International Conference on Human-Robot Interaction (HRI), March 2020. [PDF]
- Dorsa Sadigh, Anca D. Dragan, S. Shankar Sastry, Sanjit A. Seshia. Active Preference-Based Learning of Reward Functions. Proceedings of Robotics: Science and Systems (RSS), July 2017. [PDF]